



Doris易于使用的高性能且统一的分析数据库
Apache Doris
Apache Doris 是一款基于 MPP 架构的易用、高性能实时分析型数据库,以极速和易用著称。它在海量数据下仅需亚秒级响应时间即可返回查询结果,不仅支持高并发点查询场景,还能支持高吞吐量的复杂分析场景。
所有这些特性使 Apache Doris 成为报表分析、即席查询、统一数据仓库、数据湖查询加速等场景的理想工具。用户可以在 Apache Doris 上构建各种应用,例如用户行为分析、AB 测试平台、日志检索分析、用户画像分析、订单分析等。
🎉 查看 🔗所有版本,其中包含过去一年 Apache Doris 各版本的发布时间汇总。
👀 浏览 🔗官方网站,详细了解 Apache Doris 的核心功能、博客和用户案例。
📈 使用场景
如下图所示,经过各种数据集成和处理后,数据源通常存储在实时数据仓库 Apache Doris 和离线数据湖或数据仓库(Apache Hive、Apache Iceberg 或 Apache Hudi)中。
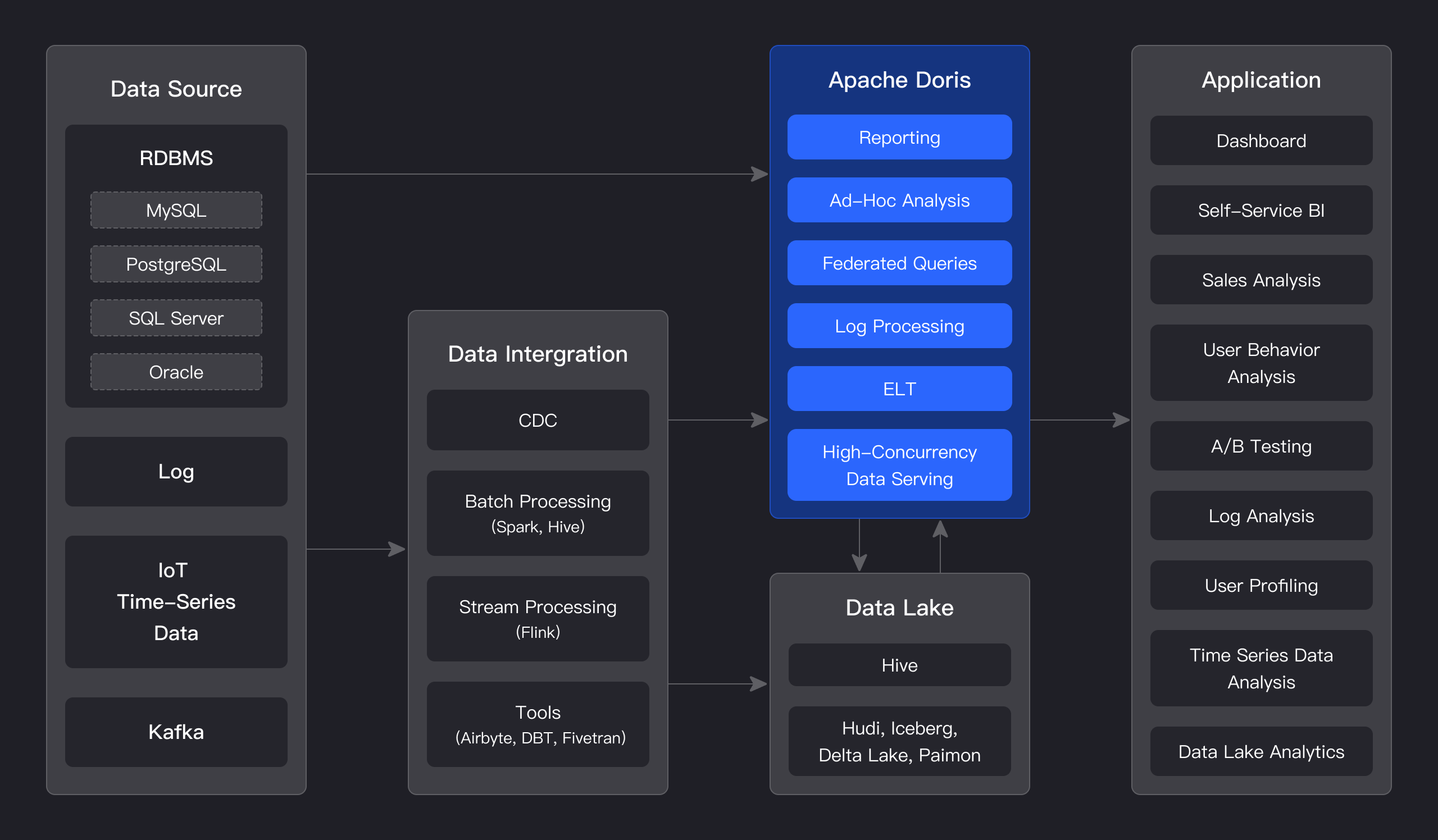
Apache Doris 广泛应用于以下场景:
-
实时数据分析:
-
实时报表与决策:Doris 为企业内部和外部提供实时更新的报表和仪表板,支持自动化流程中的实时决策。
-
临时分析:Doris 提供多维数据分析能力,支持快速商业智能分析和临时查询,帮助用户从复杂数据中快速获取洞察。
-
用户画像与行为分析:Doris 可以分析用户行为,例如参与度、留存率和转化率,同时支持群体洞察、人群筛选等行为分析场景。
-
Lakehouse 分析:
-
Lakehouse 查询加速:Doris 通过高效的查询引擎加速 Lakehouse 数据查询。
-
联合分析:Doris 支持跨多个数据源的联合查询,简化架构并消除数据孤岛。
-
实时数据处理:Doris 融合了实时数据流和批量数据处理能力,满足高并发、低延迟的复杂业务需求。
-
基于 SQL 的可观测性:
-
日志和事件分析:Doris 支持对分布式系统中的日志和事件进行实时或批量分析,帮助发现问题并优化性能。
整体架构
Apache Doris 使用 MySQL 协议,高度兼容 MySQL 语法,并支持标准 SQL。用户可以通过各种客户端工具访问 Apache Doris,并与 BI 工具无缝集成。
存储计算一体化架构
Apache Doris 的存储计算一体化架构简洁易维护。如下图所示,它仅包含两类进程:
-
前端 (FE):主要负责处理用户请求、查询解析和规划、元数据管理和节点管理任务。
-
后端 (BE):主要负责数据存储和查询执行。数据被划分为多个分片,并以多个副本的形式存储在 BE 节点上。
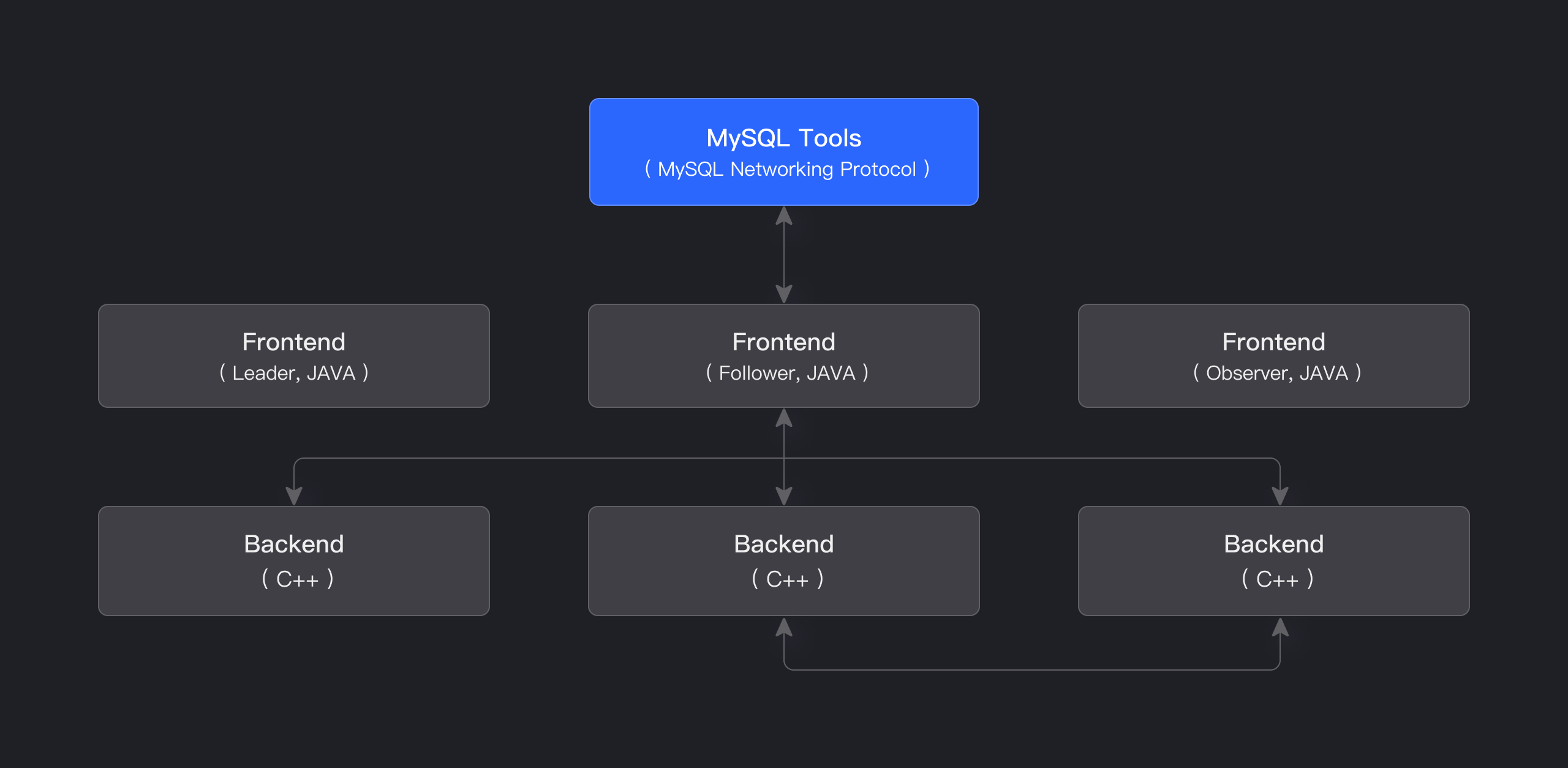
生产环境中,可以部署多个 FE 节点用于容灾。每个 FE 节点维护一份完整的元数据副本。FE 节点分为三种角色:
| 角色 | 功能 |
|---|---|
| Master | FE Master 节点负责元数据的读写操作。当 Master 节点发生元数据变更时,会通过 BDB JE 协议同步到 Follower 或 Observer 节点。 |
| Follower | Follower 节点负责读取元数据。如果 Master 节点发生故障,Follower 节点可以被选举为新的 Master 节点。 |
| Observer | Observer 节点负责读取元数据,主要用于提升查询并发量,不参与集群领导者选举。 |
FE 和 BE 进程均支持水平扩展,单集群可支持数百台机器和数十 PB 的存储容量。FE 和 BE 进程使用一致性协议,确保服务的高可用性和数据的高可靠性。存储计算一体化架构,高度集成,大幅降低分布式系统的操作复杂度。
Apache Doris 核心特性
-
高可用性:Apache Doris 的元数据和数据均采用多副本存储,并通过 quorum 协议同步数据日志。当大多数副本完成写入后,数据写入即视为成功,确保即使少数节点故障,集群依然可用。Apache Doris 支持同城和跨地域容灾,实现双集群主从模式。当部分节点发生故障时,集群可以自动隔离故障节点,避免影响集群整体可用性。
-
高兼容性:Apache Doris 高度兼容 MySQL 协议,支持标准 SQL 语法,涵盖大部分 MySQL 和 Hive 功能。这种高兼容性使用户能够无缝迁移和集成现有应用程序和工具。Apache Doris 支持 MySQL 生态系统,用户可以通过 MySQL 客户端工具连接 Doris,运维更加便捷。此外,它还支持 BI 报表工具和数据传输工具的 MySQL 协议兼容,确保数据分析和数据传输过程的高效性和稳定性。
-
实时数据仓库:基于 Apache Doris,可构建实时数据仓库服务。Apache Doris 提供秒级数据采集能力,可将上游在线事务型数据库的增量变更在秒级内捕获到 Doris 中。Doris 利用向量化引擎、MPP 架构和 Pipeline 执行引擎,提供亚秒级数据查询能力,从而构建高性能、低延迟的实时数据仓库平台。
-
统一 Lakehouse:Apache Doris 可基于数据湖或关系型数据库等外部数据源构建统一 Lakehouse 架构。Doris 统一 Lakehouse 解决方案实现了数据湖与数据仓库之间的无缝集成和数据自由流动,帮助用户直接利用数据仓库能力解决数据湖中的数据分析问题,同时充分利用数据湖的数据管理能力,提升数据价值。
-
灵活的建模:Apache Doris 提供多种建模方式,例如宽表模型、预聚合模型、星型/雪花模型等。数据导入时,可以将数据扁平化为宽表,并通过 Flink 或 Spark 等计算引擎写入 Doris;也可以直接将数据导入 Doris,通过视图、物化视图或实时多表连接等方式进行数据建模操作。
技术概述
Doris 提供高效的 SQL 接口,并完全兼容 MySQL 协议。其查询引擎基于 MPP(大规模并行处理)架构,能够高效执行复杂的分析型查询,并实现低延迟的实时查询。通过列式存储技术进行数据编码和压缩,显著优化了查询性能和存储压缩率。
接口
Apache Doris 采用 MySQL 协议,支持标准 SQL,并高度兼容 MySQL 语法。用户可以通过各种客户端工具访问 Apache Doris,并将其与 BI 工具无缝集成,包括但不限于 Smartbi、DataEase、FineBI、Tableau、Power BI 和 Apache Superset。Apache Doris 可以作为任何支持 MySQL 协议的 BI 工具的数据源。
存储引擎
Apache Doris 采用列式存储引擎,按列对数据进行编码、压缩和读取。这使得数据压缩率极高,并大大减少了不必要的数据扫描,从而更有效地利用 IO 和 CPU 资源。
Apache Doris 支持多种索引结构,以最大限度地减少数据扫描:
-
排序复合键索引:用户最多可以指定三列来组成复合排序键。这可以有效地修剪数据,更好地支持高并发报表场景。
-
最小/最大索引:此功能可在数值类型的等值查询和范围查询中实现有效的数据过滤。
-
布隆过滤器索引:此功能在高基数列的等值过滤和剪枝方面非常有效。
-
倒排索引:此功能可快速搜索任意字段。
Apache Doris 支持多种数据模型,并针对不同场景进行了优化:
-
**详细信息模型(重复键模型):**旨在满足事实表详细存储需求的详细信息数据模型。
-
**主键模型(唯一键模型):**确保唯一键;具有相同键的数据将被覆盖,从而实现行级数据更新。
-
**聚合模型(聚合键模型):**合并具有相同键的值列,通过预聚合显著提升性能。
Apache Doris 还支持强一致的单表物化视图和异步刷新的多表物化视图。单表物化视图由系统自动刷新维护,无需用户手动干预;多表物化视图可以通过集群内调度或外部调度工具定期刷新,降低数据建模的复杂度。
🔍 查询引擎
Apache Doris 拥有基于 MPP 的查询引擎,可在节点间和节点内并行执行。它支持对大型表进行分布式 Shuffle Join,从而更好地处理复杂查询。
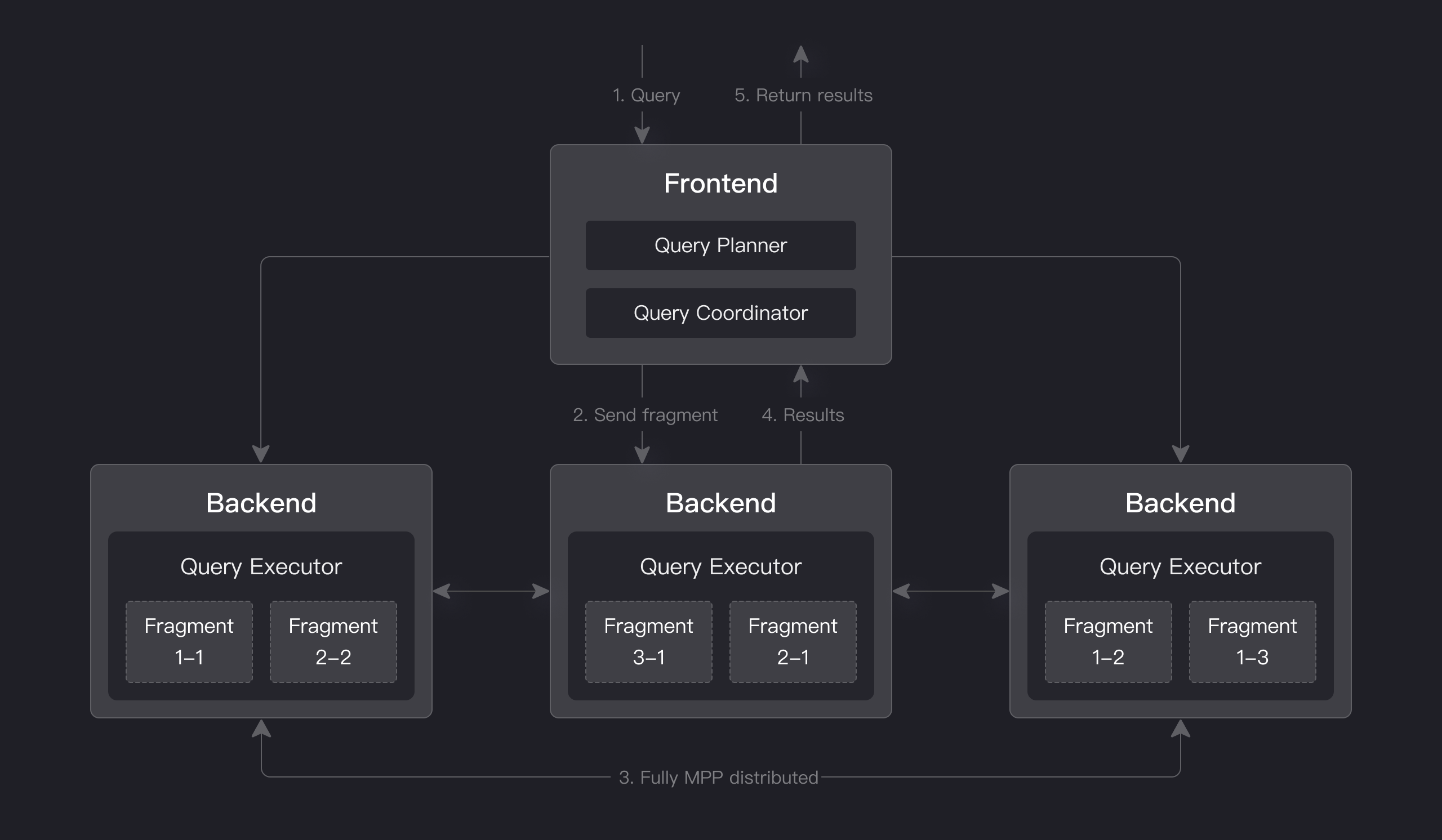
Apache Doris 的查询引擎完全矢量化,所有内存结构均采用列式布局。这可以大幅减少虚函数调用,提高缓存命中率,并有效利用 SIMD 指令。与非矢量化引擎相比,Apache Doris 在宽表聚合场景下的性能提升了 5 到 10 倍。

Apache Doris 采用自适应查询执行技术,根据运行时统计信息动态调整执行计划。例如,它可以生成运行时过滤器并将其推送至探针端。具体来说,它将过滤器推送至探针端最底层的扫描节点,从而大幅减少需要处理的数据量,并提升连接性能。Apache Doris 的运行时过滤器支持 In/Min/Max/Bloom Filter 过滤器。
Apache Doris 采用 Pipeline 执行引擎,将查询分解为多个子任务并行执行,充分利用多核 CPU 能力。同时,它通过限制查询线程数量来解决线程爆炸问题。Pipeline 执行引擎减少了数据复制和共享,优化了排序和聚合操作,从而显著提升了查询效率和吞吐量。
在优化器方面,Apache Doris 采用了 CBO(基于成本的优化器)、RBO(基于规则的优化器)和 HBO(基于历史的优化器)的组合优化策略。RBO 支持常量折叠、子查询重写、谓词下推等优化;CBO 支持连接重排序等优化;HBO 则根据历史查询信息推荐最优执行计划。多重优化措施确保 Doris 能够针对各种类型的查询枚举出高性能的查询计划。
🎆 为什么选择 Apache Doris?
-
🎯 易于使用:两个进程,无其他依赖项;在线集群扩展,自动副本恢复;兼容 MySQL 协议,并使用标准 SQL。
-
🚀 高性能:凭借列式存储引擎、现代 MPP 架构、矢量化查询引擎、预聚合物化视图和数据索引,实现极快的低延迟和高吞吐量查询性能。
-
🖥️ 单一统一:单个系统即可支持实时数据服务、交互式数据分析和离线数据处理等场景。
-
⚛️ 联合查询:支持 Hive、Iceberg、Hudi 等数据湖以及 MySQL、Elasticsearch 等数据库的联合查询。
-
⏩ 丰富的数据导入方式:支持从 HDFS/S3 批量导入,以及从 MySQL Binlog/Kafka 流式导入;支持通过 HTTP 接口进行微批量写入,以及通过 JDBC 中的 Insert 进行实时写入。
-
🚙 丰富的生态:Spark 使用 Spark-Doris-Connector 读写 Doris;Flink-Doris-Connector 使 Flink CDC 能够实现对 Doris 的 Exactly-Once 数据写入;提供 DBT Doris Adapter,用于将 Doris 中的数据与 DBT 进行转换。
🙌 贡献者
Apache Doris 已于 2022 年 6 月成功从 Apache 孵化器毕业,成为顶级项目。
我们衷心感谢🔗社区贡献者对 Apache Doris 的贡献。
贡献图 (https://contrib.rocks/image?repo=apache/doris) (https://github.com/apache/doris/graphs/contributors)
👨👩👧👦 用户
Apache Doris 现已在中国及全球拥有广泛的用户群,截至目前,Apache Doris 已在全球数千家公司的生产环境中使用。 中国市值或估值前 50 强的互联网公司中,超过 80% 的公司长期使用 Apache Doris,包括百度、美团、小米、京东、字节跳动、腾讯、网易、快手、新浪、360、米哈游和贝壳找房。此外,它还在金融、能源、制造和电信等一些传统行业得到广泛应用。
Apache Doris 的用户:🔗用户
在 Apache Doris 网站上添加您的公司徽标:🔗添加您的公司
👣 开始使用
📚 文档
所有文档 🔗文档
⬇️ 下载
所有发行版和二进制版本 🔗下载
🗄️ 编译
查看如何编译 🔗编译)
📮 安装
查看如何安装和部署 🔗安装和部署
🧩 组件
📝 Doris Connector
Doris 支持 Spark/Flink 通过 Connector 读取存储在 Doris 中的数据,也支持通过 Connector 将数据写入 Doris。
🌈 社区与支持
📤 订阅邮件列表
邮件列表是 Apache 社区中最受认可的沟通方式。了解如何 🔗订阅邮件列表
🙋 报告问题或提交拉取请求
如果您遇到任何问题,请随时提交 🔗GitHub Issue 或将其发布到 🔗GitHub Discussion,并通过提交 🔗Pull Request 来解决问题。
🍻 如何贡献
我们欢迎您的建议、评论(包括批评)、意见和贡献。请参阅🔗如何贡献 和 🔗代码提交指南
⌨️ Doris 改进提案 (DSIP)
🔗Doris 改进提案 (DSIP) 可以理解为所有主要功能更新或改进的设计文档集合。
🔑 后端 C++ 编码规范
🔗 应严格遵循 后端 C++ 编码规范,这将有助于我们实现更高质量的代码。
💬 联系我们
请通过以下邮件列表联系我们。
| 姓名 | 范围 | |||
|---|---|---|---|---|
| dev@doris.apache.org | 开发相关讨论 | 订阅 | 取消订阅 | 档案 |
🧰 链接
- Apache Doris 官方网站 - Site
- 开发者邮件列表 - dev@doris.apache.org。发送邮件至 dev-subscribe@doris.apache.org,按照回复即可订阅邮件列表。
- Slack 频道 - 加入 Slack
- Twitter - 关注 @doris_apache
📜 许可证
注意
部分第三方依赖项的许可证与 Apache 2.0 许可证不兼容。因此,您需要禁用部分 Doris 功能才能符合 Apache 2.0 许可证。详情请参阅thirdparty/LICENSE.txt文件。