



ClickHouse是一个实时分析数据库管理系统
ClickHouse® 是一个开源的列式数据库管理系统,可以实时生成分析数据报告。
特点
每秒提取数百万行数据。处理最繁重的并发工作负载。所有这些都不会影响查询速度。
- 创建面向用户的仪表板和应用程序,并实现即时响应
- 利用最新数据推动明智的业务决策
- 轻松在最多样化、高基数的数据集上运行基于 SQL 的分析
- 无缝集成来自各种来源的静态或流数据
- 使用您常用的可视化工具,例如 Grafana、Tableau、Superset 等
如何安装(Linux、macOS、FreeBSD)
curl https://clickhouse.com/ | sh行式存储 vs. 列式存储
只有正确的数据“方向”才能实现如此高的性能。
数据库可以按行或列存储数据。
在行式数据库中,连续的表行按顺序依次存储。这种布局允许快速检索行,因为每行的列值都存储在一起。
ClickHouse 是一个列式数据库。在这样的系统中,表以列的集合形式存储,即每列的值按顺序依次存储。这种布局使得恢复单行数据更加困难(因为现在行值之间存在间隙),但诸如过滤或聚合之类的列操作比在行式数据库中要快得多。
最好用一个运行超过 1 亿行真实匿名网络分析数据的示例查询来解释这种差异:
SELECT MobilePhoneModel, COUNT() AS c
FROM metrica.hits
WHERE
RegionID = 229
AND EventDate >= '2013-07-01'
AND EventDate <= '2013-07-31'
AND MobilePhone != 0
AND MobilePhoneModel not in ['', 'iPad']
GROUP BY MobilePhoneModel
ORDER BY c DESC
LIMIT 8;您可以在 ClickHouse SQL Playground 上运行此查询,该查询从 100 多个现有列中选择并过滤几个列,并在几毫秒内返回结果:
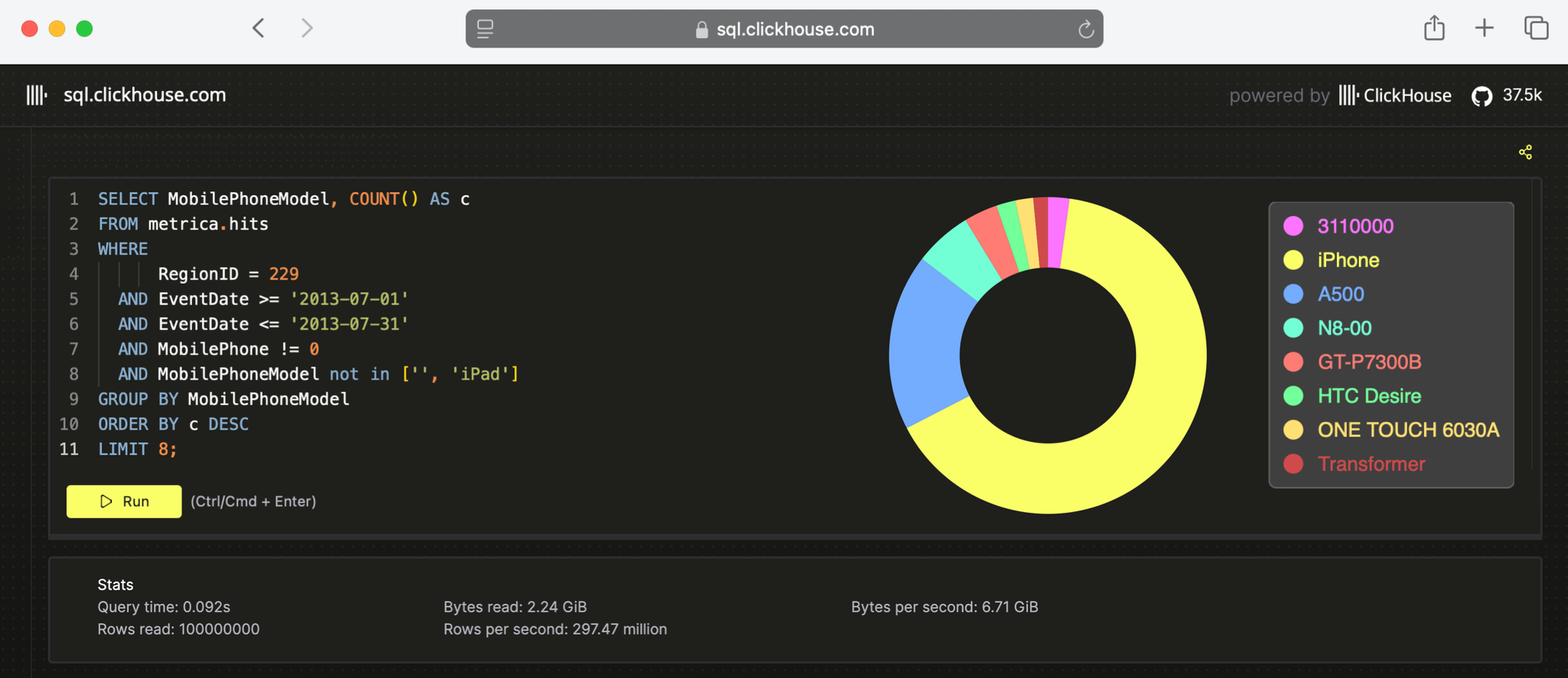
正如您在上图的统计部分所看到的,该查询在 92 毫秒内处理了 1 亿行,吞吐量约为每秒超过 10 亿行,或每秒传输的数据略低于 7 GB。
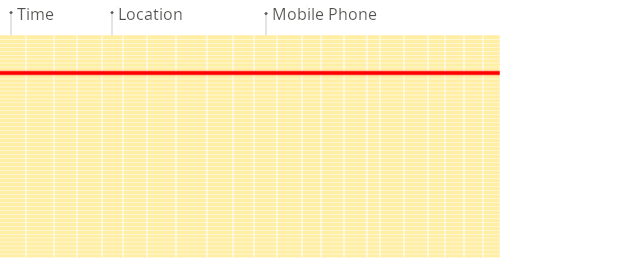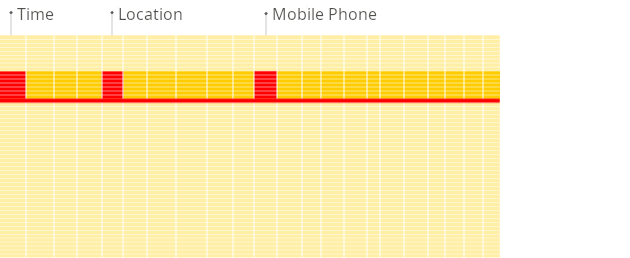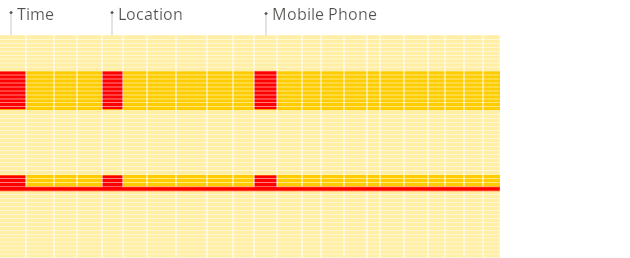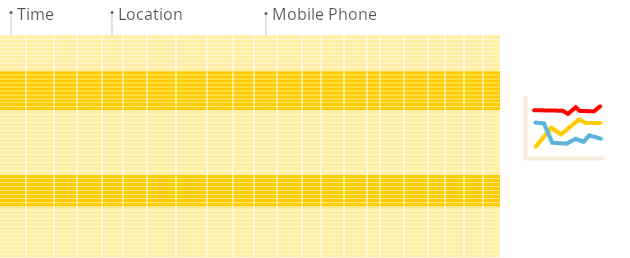
面向行的 DBMS
在面向行的数据库中,即使上述查询仅处理现有列中的少数列,系统仍然需要将其他现有列的数据从磁盘加载到内存。这是因为数据以块(通常大小固定,例如 4 KB 或 8 KB)的形式存储在磁盘上。块是从磁盘读取到内存的最小数据单位。当应用程序或数据库请求数据时,操作系统的磁盘 I/O 子系统会从磁盘读取所需的块。即使只需要块的一部分,整个块也会被读入内存(这是由于磁盘和文件系统的设计决定的):
数据复制和完整性
ClickHouse 采用异步多主复制方案,确保数据在多个节点上冗余存储。写入任何可用副本后,所有剩余副本都会在后台检索其副本。系统在不同的副本上维护相同的数据。大多数故障后的恢复是自动执行的,在复杂情况下则以半自动方式执行。
基于角色的访问控制
ClickHouse 使用 SQL 查询实现用户帐户管理,并允许基于角色的访问控制配置,类似于 ANSI SQL 标准和流行的关系数据库管理系统中的配置。
SQL 支持
ClickHouse 支持基于 SQL 的声明式查询语言,该语言在许多情况下与 ANSI SQL 标准完全相同。支持的查询子句包括 GROUP BY、ORDER BY、FROM 中的子查询、JOIN 子句、IN 运算符、窗口函数和标量子查询。
近似计算
ClickHouse 提供了以准确性换取性能的方法。例如,它的一些聚合函数可以近似地计算不同值的数量、中位数和分位数。此外,查询可以针对数据样本运行,以快速计算出近似结果。最后,聚合可以针对有限数量的键运行,而不是针对所有键运行。根据键分布的倾斜程度,这可以提供相当准确的结果,并且比精确计算消耗的资源少得多。
自适应连接算法
ClickHouse 会自适应地选择连接算法:它首先使用快速哈希连接,如果存在多个大表,则回退到合并连接。
卓越的查询性能
ClickHouse 以其极快的查询性能而闻名。要了解 ClickHouse 如此快速的原因,请参阅“ClickHouse 为何如此快速?”指南。
实用链接
- 官方网站 在主页上提供了 ClickHouse 的简要概述。
- ClickHouse Cloud ClickHouse 即服务,由其创建者和维护者构建。
- 教程 展示了如何设置和查询小型 ClickHouse 集群。
- 文档 提供了更深入的信息。
- YouTube 频道 以视频形式提供了大量关于 ClickHouse 的内容。
- Slack 和 Telegram 允许与 ClickHouse 用户实时聊天。
- 博客 包含各种与 ClickHouse 相关的文章,以及活动公告和报告。
- Bluesky 和 X 用于查看简短新闻。
- 代码浏览器 (github.dev) 具有语法高亮功能,由 github.dev 提供支持。
- 联系人 可以帮助您解答任何问题。