



EasyOCR文字识别
EasyOCR
即用型 OCR,支持 80 多种语言和所有流行的书写文字,包括:拉丁文、中文、阿拉伯文、天城文、西里尔文等。
新功能
- 2024 年 9 月 24 日 - 版本 1.7.2
- 修复多项兼容性问题
后续更新
- 支持手写文本
Examples


安装
使用 pip 安装
最新稳定版本:
pip install easyocr最新开发版本:
pip install git+https://github.com/JaidedAI/EasyOCR.git注 1:对于 Windows 系统,请先按照官方说明(https://pytorch.org)安装 torch 和 torchvision。在 pytorch 官网上,请务必选择正确的 CUDA 版本。如果您只想在 CPU 模式下运行,请选择 CUDA = None。
注 2:我们还提供了一个 Dockerfile(此处)。(https://github.com/JaidedAI/EasyOCR/blob/master/Dockerfile)。
用法
import easyocr
reader = easyocr.Reader(['ch_sim','en']) # this needs to run only once to load the model into memory
result = reader.readtext('chinese.jpg')输出将采用列表格式,每一项分别代表一个边界框、检测到的文本和置信度。
[([[189, 75], [469, 75], [469, 165], [189, 165]], '愚园路', 0.3754989504814148),
([[86, 80], [134, 80], [134, 128], [86, 128]], '西', 0.40452659130096436),
([[517, 81], [565, 81], [565, 123], [517, 123]], '东', 0.9989598989486694),
([[78, 126], [136, 126], [136, 156], [78, 156]], '315', 0.8125889301300049),
([[514, 126], [574, 126], [574, 156], [514, 156]], '309', 0.4971577227115631),
([[226, 170], [414, 170], [414, 220], [226, 220]], 'Yuyuan Rd.', 0.8261902332305908),
([[79, 173], [125, 173], [125, 213], [79, 213]], 'W', 0.9848111271858215),
([[529, 173], [569, 173], [569, 213], [529, 213]], 'E', 0.8405593633651733)]注 1:['ch_sim','en'] 是您想要读取的语言列表。您可以一次传递多种语言,但并非所有语言都可以一起使用。
英语与所有语言兼容,并且具有共同字符的语言通常彼此兼容。
注 2:除了文件路径 chinese.jpg,您还可以传递 OpenCV 图像对象(numpy 数组)或以字节形式存储的图像文件。原始图像的 URL 也是可以接受的。
注 3:reader = easyocr.Reader(['ch_sim','en']) 行用于将模型加载到内存中。这需要一些时间,但只需运行一次。
您还可以设置 detail=0 以获得更简单的输出。
reader.readtext('chinese.jpg', detail = 0)Result:
['愚园路', '西', '东', '315', '309', 'Yuyuan Rd.', 'W', 'E']所选语言的模型权重将自动下载,您也可以
从 模型中心 手动下载,并将其保存到“~/.EasyOCR/model”文件夹中。
如果您没有 GPU,或者 GPU 内存不足,您可以通过添加“gpu=False”以仅 CPU 模式运行模型。
reader = easyocr.Reader(['ch_sim','en'], gpu=False)在命令行上运行
$ easyocr -l ch_sim en -f chinese.jpg --detail=1 --gpu=True训练/使用您自己的模型
对于识别模型,请阅读此处。
对于检测模型 (CRAFT),请阅读此处。
实施路线图
- 手写支持
- 重构代码以支持可切换的检测和识别算法
API 应该尽可能简单
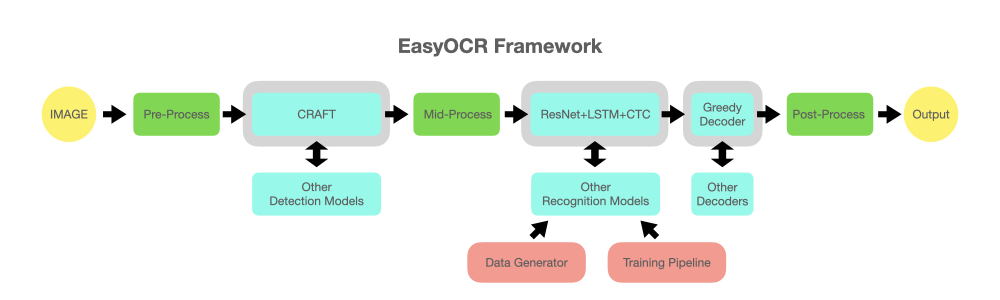
reader = easyocr.Reader(['en'], detection='DB', recognition = 'Transformer')我们的目标是能够将任何最先进的模型嵌入 EasyOCR。很多天才都在尝试开发更好的检测/识别模型,但我们并非试图成为天才。我们只是想让他们的作品快速免费地向公众开放。(好吧,我们相信大多数天才都希望他们的工作能够尽快/尽可能大地产生积极的影响)流程应该如下图所示。灰色插槽是可替换的浅蓝色模块的占位符。
致谢和参考文献
本项目基于多篇论文和开源库的研究和代码。
所有深度学习执行均基于 Pytorch。 :heart:
检测执行使用了来自官方代码库及其论文的CRAFT算法(感谢@clovaai的@YoungminBaek)。我们也使用了他们的预训练模型。训练脚本由@gmuffiness提供。
识别模型是CRNN(论文)。它由三个主要部分组成:特征提取(我们目前使用 Resnet)和 VGG、序列标记 (LSTM) 和解码 (CTC)。用于执行识别的训练流程是 deep-text-recognition-benchmark 框架的修改版本。(感谢 @ku21fan 来自 @clovaai)这个代码库是一颗值得更多认可的珍宝。
Beam 搜索代码基于此 代码库 和他的 博客。(感谢 @githubharald)
数据合成基于 TextRecognitionDataGenerator。(感谢 @Belval)
此外,还有一篇关于 CTC 的文章,来自 Distill.pub,此处。
想要贡献力量吗?
让我们携手推动人类进步,让人工智能惠及每个人!
三种贡献方式:
**程序员:**请提交 PR 以解决小错误/改进问题。对于较大的问题,请先提交 Issue 与我们讨论。我们列出了所有可能的错误/改进问题,并标记了 'PR WELCOME'。
**用户:**请告诉我们 EasyOCR 如何为您/您的组织带来益处,以鼓励我们进一步开发。您也可以在 Issue 版块 发布失败案例,以帮助改进未来的模型。
**技术负责人/专家:**如果您觉得这个库有用,请分享! (请参阅 Yann Lecun 的帖子 关于 EasyOCR 的内容)
新语言请求指南
要请求新语言,我们需要您发送包含以下两个文件的 PR:
- 在文件夹 easyocr/character 中,
我们需要包含所有字符列表的“yourlanguagecode_char.txt”。请参阅该文件夹中其他文件的格式示例。 - 在文件夹 easyocr/dict 中,
我们需要包含您语言单词列表的“yourlanguagecode.txt”。
平均而言,每种语言都有约 30,000 个单词,而流行语言则有超过 50,000 个单词。
此文件中的单词越多越好。
如果您的语言有一些独特的元素(例如 1. 阿拉伯语:字符连接时会改变形状 + 从右向左书写 2. 泰语:有些字符需要在横线上,有些需要在横线下),请尽力告知我们并/或提供有用的链接。关注细节对于构建一个真正有效的系统至关重要。
最后,请理解,我们的优先考虑对象是流行语言或字符间存在大量共通点的语言集合(如果您的语言存在这种情况,也请告知我们)。我们至少需要一周时间来开发新模型,因此您可能需要等待一段时间才能发布新模型。
请参阅正在开发中的语言列表
Github Issues
由于资源有限,超过 6 个月的 Issue 将自动关闭。如果问题至关重要,请重新提交 Issue。