



Zstandard一种快速无损压缩算法并实现更高的压缩比
Zstandard
Zstandard,简称“zstd”,是一种快速无损压缩算法,旨在实现 zlib 级别的实时压缩场景,并实现更高的压缩比。它由 Huff0 和 FSE 库 提供的超快速熵阶段支持。
Zstandard 的格式稳定,并记录在 RFC8878 中。目前已有多个独立实现。此代码库代表参考实现,以开源双 BSD 或 GPLv2 许可的 C 库的形式提供,以及一个用于生成和解码 .zst、.gz、.xz 和 .lz4 文件的命令行实用程序。
如果您的项目需要其他编程语言,Zstandard 主页 上提供了已知端口和绑定的列表。
基准测试
作为参考,我们在一台搭载 Core i7-9700K CPU @ 4.9GHz 的台式机上,并运行 Ubuntu 24.04(Linux 6.8.0-53-generic)操作系统,并使用 lzbench(一款由 @inikep 开发的开源内存基准测试程序)使用 gcc 14.2.0 编译,在 Silesia 压缩语料库 上测试并比较了几种快速压缩算法。
| 压缩机名称 | 比率 | 压缩 | 解压缩。 |
|---|---|---|---|
| zstd 1.5.7 -1 | 2.896 | 510 MB/s | 1550 MB/s |
| brotli 1.1.0 -1 | 2.883 | 290 MB/s | 425 MB/s |
| zlib 1.3.1 -1 | 2.743 | 105 MB/s | 390 MB/s |
| zstd 1.5.7 --fast=1 | 2.439 | 545 MB/s | 1850 MB/s |
| quicklz 1.5.0 -1 | 2.238 | 520 MB/s | 750 MB/s |
| zstd 1.5.7 --fast=4 | 2.146 | 665 MB/s | 2050 MB/s |
| lzo1x 2.10 -1 | 2.106 | 650 MB/s | 780 MB/s |
| lz4 1.10.0 | 2.101 | 675 MB/s | 3850 MB/s |
| snappy 1.2.1 | 2.089 | 520 MB/s | 1500 MB/s |
| lzf 3.6 -1 | 2.077 | 410 MB/s | 820 MB/s |
使用 --fast=# 指定的负压缩级别,可以提供更快的压缩和解压速度,但会降低压缩率。
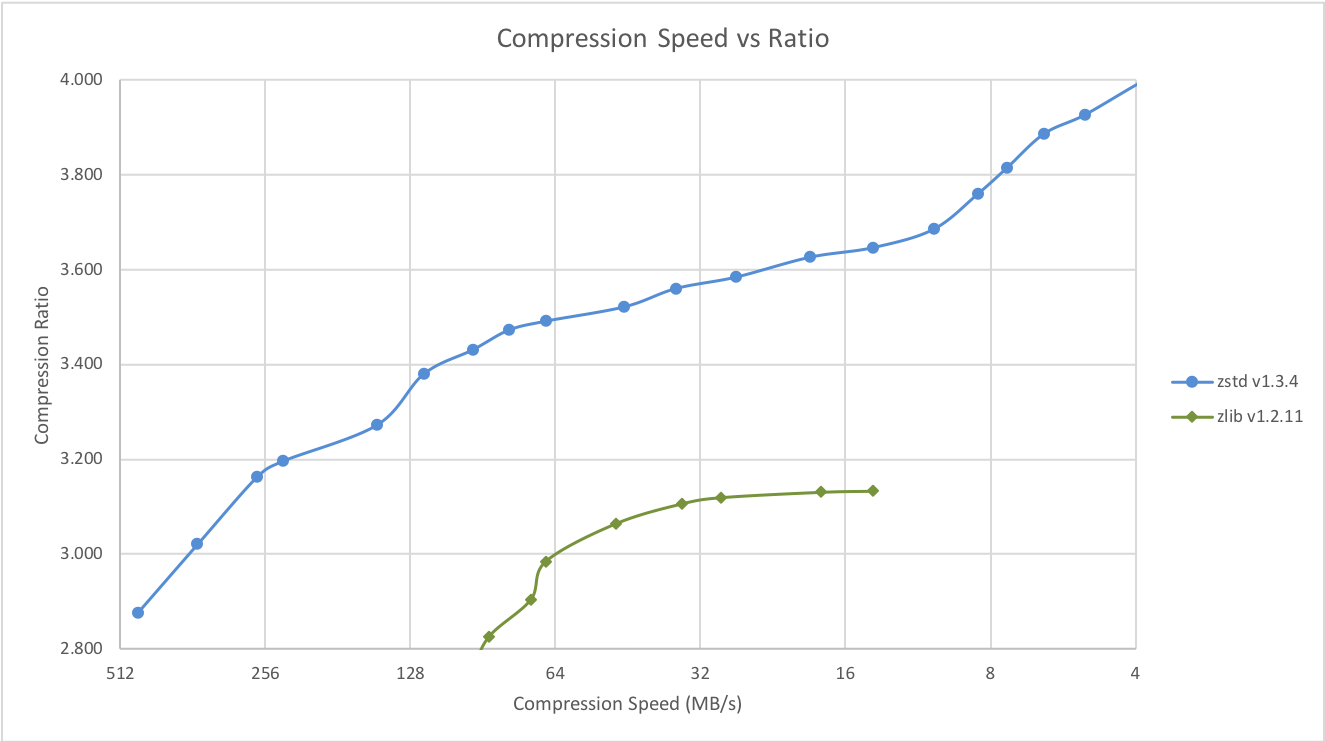
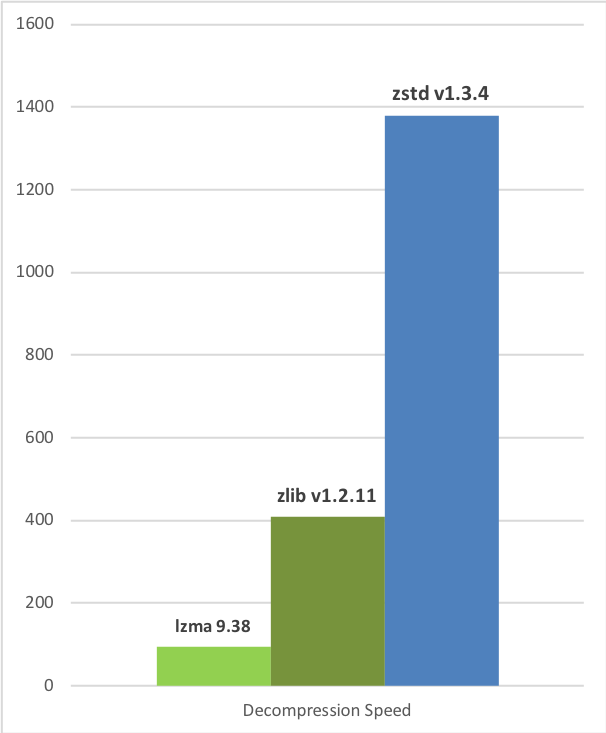
Zstd 也可以提供更高的压缩率,但会降低压缩速度。速度与压缩率之间的权衡可以通过小增量进行配置。解压速度保持不变,并且在所有设置下都大致相同,这是大多数 LZ 压缩算法(例如 zlib 或 lzma)的共同特性。
以下测试在运行 Linux Debian(Linux 版本 4.14.0-3-amd64)的服务器上运行,该服务器配备 Core i7-6700K CPU @ 4.0GHz,并使用 lzbench(由 @inikep 开发的开源内存基准测试程序,使用 gcc 7.3.0 编译)在 Silesia 压缩语料库 上运行。
| 压缩速度与压缩率 | 解压速度 |
|---|---|
 |
 |
其他一些算法可以在较慢的速度下产生更高的压缩比,因此不在图表范围内。
小数据压缩案例
之前的图表提供了适用于典型文件和流场景(数 MB)的结果。小数据则有不同的视角。
需要压缩的数据量越小,压缩难度就越大。这个问题是所有压缩算法都面临的共同问题,原因是压缩算法会从过去的数据中学习如何压缩未来的数据。但在新数据集开始时,没有“过去”可以借鉴。
为了解决这个问题,Zstd 提供了一种“训练模式”,可用于针对特定类型的数据调整算法。
训练 Zstandard 是通过提供一些样本(每个样本一个文件)来实现的。训练结果存储在一个名为“字典”的文件中,必须在压缩和解压缩之前加载该文件。
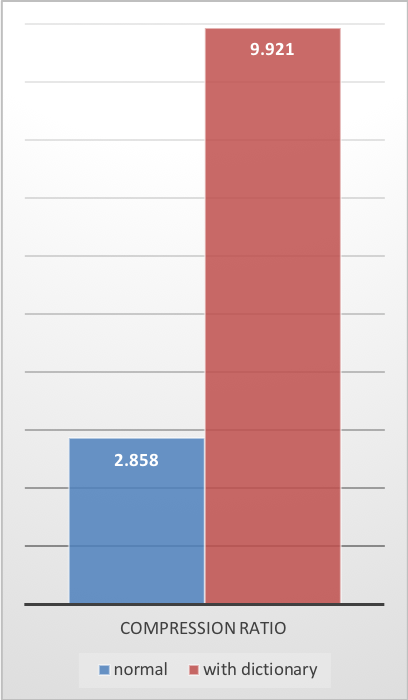
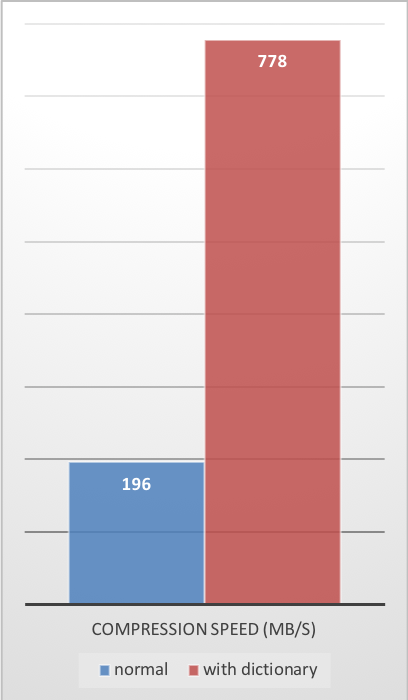
使用此字典,可以显著提高小数据的压缩率。
以下示例使用了 github-users 样本集,该样本集由 github 公共 API 创建。
该样本集包含大约 10,000 条记录,每条记录大小约为 1KB。
| 压缩率 | 压缩速度 | 解压速度 |
|---|---|---|
 |
 |
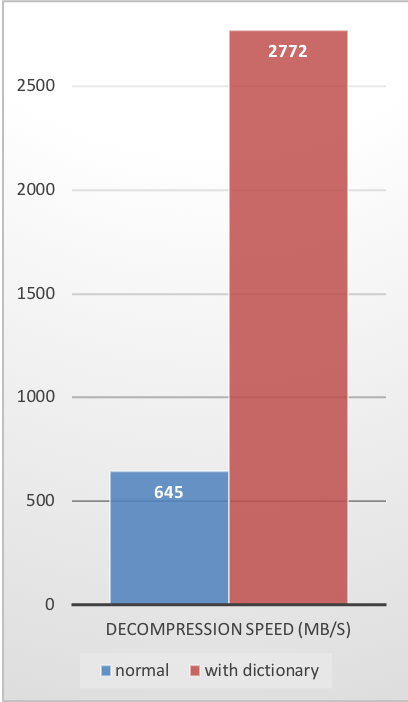 |
这些压缩增益是在提供更快的压缩和解压缩速度的同时实现的。
如果一组小数据样本之间存在某种相关性,训练就会有效。字典越针对特定数据,其效率就越高(不存在“通用字典”)。
因此,为每种类型的数据部署一个字典将带来最大的收益。
字典增益在最初的几 KB 数据中最为有效。然后,压缩算法将逐渐利用先前解码的内容来更好地压缩文件的其余部分。
字典压缩方法:
- 创建字典
zstd --train FullPathToTrainingSet/* -o dictionaryName
- 使用字典压缩
zstd -D dictionaryName FILE
- 使用字典解压
zstd -D dictionaryName --decompress FILE.zst
构建说明
make 是本项目官方维护的构建系统。所有其他构建系统均“兼容”并由第三方维护,它们在高级选项上可能略有不同。如果您的系统允许,请优先使用 make 来构建 zstd 和 libzstd。
Makefile
假设您的系统支持标准 make(或 gmake),在根目录中调用 make 将在根目录中生成 zstd 命令行工具。它还会在 lib/ 目录中创建 libzstd。
其他标准目标包括:
make install:创建并安装 zstd 命令行工具、库和手册页make check:创建并运行zstd,并在本地平台上测试其行为
Makefile 遵循 GNU 标准 Makefile 约定,允许分阶段安装、标准编译标志、目录变量和命令变量。
对于高级用例,控制二进制文件生成和安装路径的专用标志已记录在lib/README.md(针对 libzstd 库)和 programs/README.md(针对 zstd 命令行工具)。
cmake
cmake 项目生成器在 build/cmake 目录中提供。它可以生成 Makefile 或其他构建脚本,用于创建 zstd 二进制文件以及 libzstd 动态库和静态库。
默认情况下,CMAKE_BUILD_TYPE 设置为 Release。
支持 Fat (Universal2) 输出
zstd 可以通过 CMake 的 Universal2 支持,构建和安装同时支持 Apple Silicon (M1/M2) 和 Intel 芯片的版本。要执行 Fat/Universal2 构建和安装,请使用以下命令:
cmake -B build-cmake-debug -S build/cmake -G Ninja -DCMAKE_OSX_ARCHITECTURES="x86_64;x86_64h;arm64"
cd build-cmake-debug
ninja
sudo ninja installMeson
build/meson 目录中提供了一个 Meson 项目。请按照该目录中的构建说明进行操作。
您还可以查看 .travis.yml 文件,以获取有关如何使用 Meson 构建此项目的示例。
请注意,默认构建类型为 release。
VCPKG
您可以构建并安装 zstd vcpkg 依赖管理器:
git clone https://github.com/Microsoft/vcpkg.git
cd vcpkg
./bootstrap-vcpkg.sh
./vcpkg integrate install
./vcpkg install zstdvcpkg 中的 zstd 移植由 Microsoft 团队成员和社区贡献者负责保持更新。
如果版本已过期,请在 vcpkg 仓库中创建问题或拉取请求。
Conan
您可以安装 zstd 的预构建二进制文件,也可以使用 Conan 从源代码构建。使用以下命令:
conan install --requires="zstd/[*]" --build=missingzstd Conan 配方由 Conan 维护者和社区贡献者负责保持更新。如果版本已过期,请在 ConanCenterIndex 仓库中创建问题或拉取请求。
Buck
您可以通过 buck 构建 zstd 二进制文件,方法是在仓库根目录执行:buck build programs:zstd。输出的二进制文件位于 buck-out/gen/programs/。
Bazel
您可以使用 Bazel 中央仓库 中托管的模块,轻松地将 zstd 集成到您的 Bazel 项目中。
测试
您可以通过运行 make check 来快速运行本地冒烟测试。如果您无法使用 make,请从 src/tests 目录执行 playTest.sh 脚本。测试脚本需要两个环境变量$ZSTD_BIN 和 $DATAGEN_BIN 来定位 zstd 和 datagen 二进制文件。有关持续集成测试的信息,请参阅 TESTING.md。
状态
Zstandard 目前已部署在 Facebook 和许多其他大型云基础设施中。它持续运行,以压缩多种格式和用例的大量数据。Zstandard 被认为在生产环境中是安全的。