



实时本地语音转文本、翻译和人声识别
WhisperLiveKit
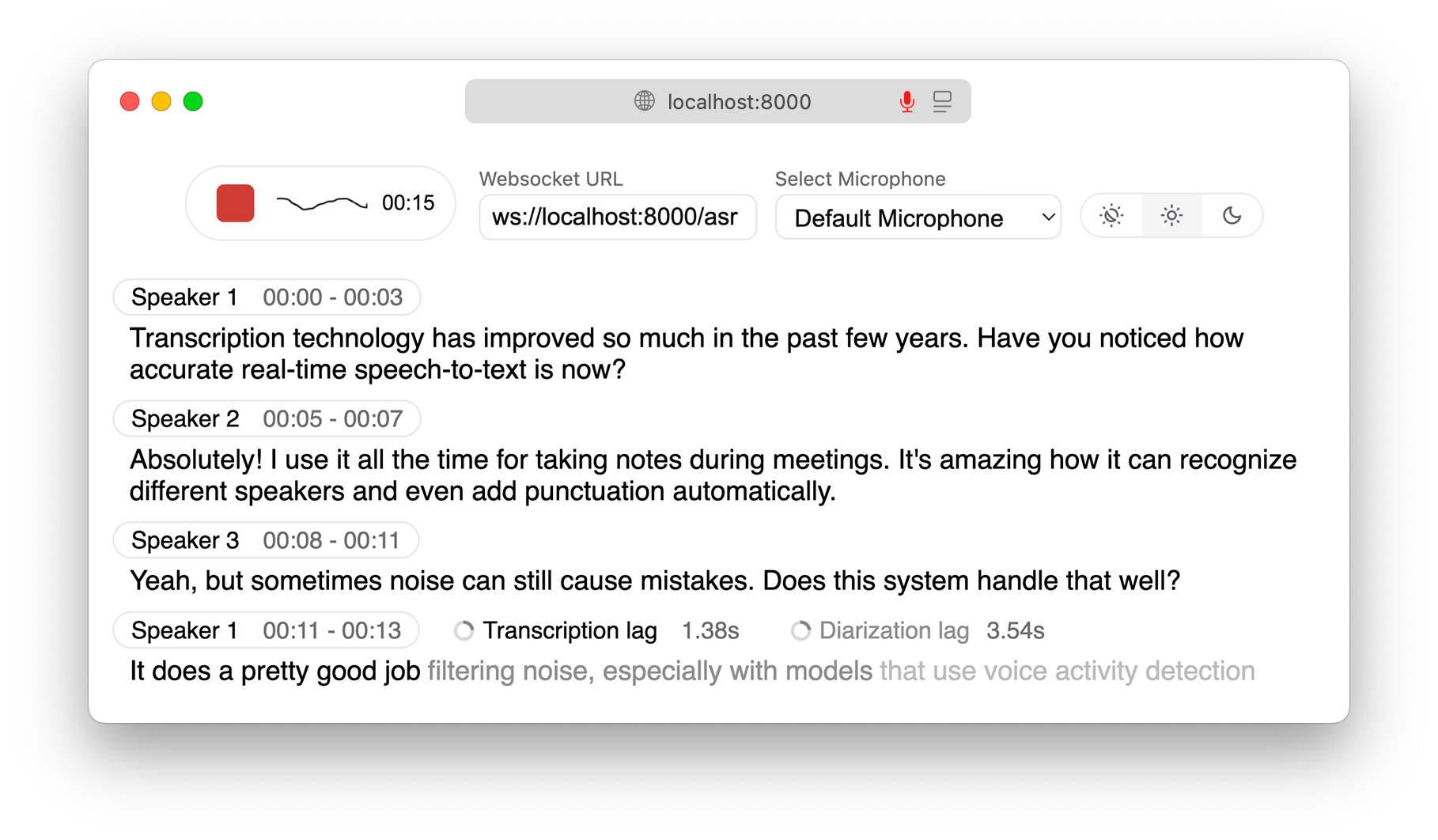
实时、完全本地语音转文本,支持语音识别
实时语音转录直接发送到您的浏览器,带有可立即使用的后端+服务器和简单的前端。 ✨
Powered by Leading Research:
- SimulStreaming (SOTA 2025) - 基于 AlignAtt 策略的超低延迟转录
- WhisperStreaming (SOTA 2023) - 基于 LocalAgreement 策略的低延迟转录
- Streaming Sortformer (SOTA 2025) - 高级实时说话人分类
- Diart (SOTA 2021) - 实时说话人分类
- Silero VAD (2024) - 企业级语音活动检测
为什么不在每个音频批次上运行一个简单的 Whisper 模型呢? Whisper 的设计目标是处理完整的话语,而不是实时的语段。处理小片段会丢失上下文,在音节中间切断单词,并且转录质量很差。WhisperLiveKit 采用最先进的同步语音研究技术,实现智能缓冲和增量处理。
架构
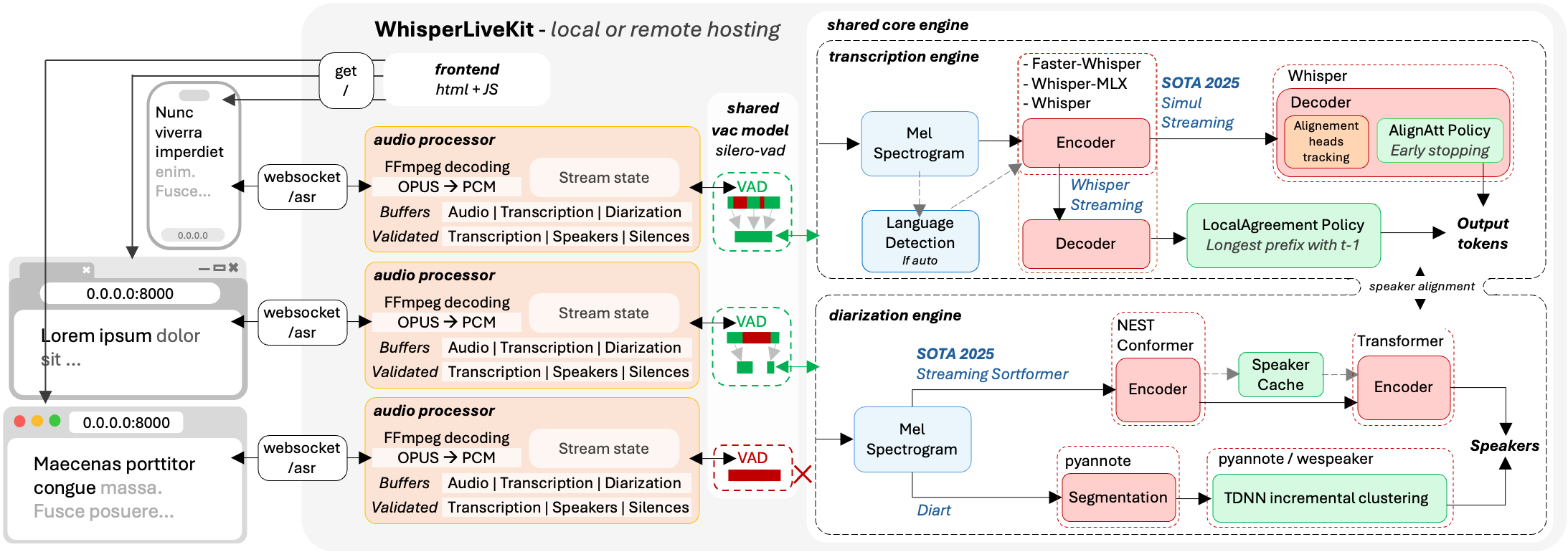
后端支持多个并发用户。语音活动检测功能可在未检测到语音时减少开销。
安装和快速入门
pip install whisperlivekit需要 FFmpeg,必须在使用 WhisperLiveKit 之前安装。
操作系统 如何安装 Ubuntu/Debian sudo apt install ffmpegMacOS brew install ffmpegWindows 从 https://ffmpeg.org/download.html 下载 .exe 并添加到 PATH 环境变量
快速入门
- 启动转录服务器:
whisperlivekit-server --model base --language en- 打开浏览器并导航至
http://localhost:8000。开始说话,实时观看您的语音!
- 请参阅 tokenizer.py 获取所有可用语言的列表。
- 有关 HTTPS 要求,请参阅 参数 部分中的 SSL 配置选项。
可选依赖项
| 可选 | pip install |
|---|---|
| 使用 Sortformer 进行说话人分类 | git+https://github.com/NVIDIA/NeMo.git@main#egg=nemo_toolkit[asr] |
| Apple Silicon 优化后端 | mlx-whisper |
| [不推荐] 使用 Diart 进行说话人分类 | diart |
| [不推荐] 原始 Whisper 后端 | whisper |
| [不推荐] 改进的时间戳后端 | whisper-timestamped |
| OpenAI API 后端 | openai |
请参阅下面的参数和配置,了解如何使用它们。
使用示例
命令行界面:使用各种选项启动转录服务器:
# Use better model than default (small)
whisperlivekit-server --model large-v3
# Advanced configuration with diarization and language
whisperlivekit-server --host 0.0.0.0 --port 8000 --model medium --diarization --language frPython API 集成:检查 basic_server 以获取有关如何使用函数和类的更完整示例。
from whisperlivekit import TranscriptionEngine, AudioProcessor, parse_args
from fastapi import FastAPI, WebSocket, WebSocketDisconnect
from fastapi.responses import HTMLResponse
from contextlib import asynccontextmanager
import asyncio
transcription_engine = None
@asynccontextmanager
async def lifespan(app: FastAPI):
global transcription_engine
transcription_engine = TranscriptionEngine(model="medium", diarization=True, lan="en")
yield
app = FastAPI(lifespan=lifespan)
async def handle_websocket_results(websocket: WebSocket, results_generator):
async for response in results_generator:
await websocket.send_json(response)
await websocket.send_json({"type": "ready_to_stop"})
@app.websocket("/asr")
async def websocket_endpoint(websocket: WebSocket):
global transcription_engine
# Create a new AudioProcessor for each connection, passing the shared engine
audio_processor = AudioProcessor(transcription_engine=transcription_engine)
results_generator = await audio_processor.create_tasks()
results_task = asyncio.create_task(handle_websocket_results(websocket, results_generator))
await websocket.accept()
while True:
message = await websocket.receive_bytes()
await audio_processor.process_audio(message) 前端实现:此软件包包含一个 HTML/JavaScript 实现,此处。您也可以使用 from whisperlivekit import get_inline_ui_html & page = get_inline_ui_html() 导入它。
参数和配置
您可以更改一些重要的参数。但是您应该更改哪些参数呢?
--model的大小。列表和建议见 此处--language的列表。列表见 此处。如果您使用auto,模型会尝试自动检测语言,但结果往往偏向英语。--backend?如果simulstreaming无法正常工作,或者您希望避免双重许可证要求,您可以切换到--backend fastest-whisper。--warmup-file(如果您有)--task translate(用于翻译成英文)--host、--port、--ssl-certfile、--ssl-keyfile(如果您设置了服务器)--diarization(如果您想使用)。
其余的我不推荐。但以下是一些可选的选项。
| 参数 | 描述 | 默认值 |
|---|---|---|
--model |
Whisper 模型大小。 | small |
--language |
源语言代码或 auto |
auto |
--task |
transcribe 或 translate |
transcribe |
--backend |
处理后端 | simulstreaming |
--min-chunk-size |
最小音频块大小(秒) | 1.0 |
--no-vac |
禁用语音活动控制器 | False |
--no-vad |
禁用语音活动检测 | False |
--warmup-file |
模型预热的音频文件路径 | jfk.wav |
--host |
服务器主机地址 | localhost |
--port |
服务器端口 | 8000 |
--ssl-certfile |
SSL 证书文件路径(用于支持 HTTPS) | None |
--ssl-keyfile |
SSL 私钥文件路径(用于支持 HTTPS) | None |
| SimulStreaming 后端选项 | 描述 | 默认 |
|---|---|---|
--disable-fast-encoder |
为编码器禁用 Faster Whisper 或 MLX Whisper 后端(如果已安装)。推理速度可能会较慢,但在 GPU 内存有限的情况下很有用 | False |
--frame-threshold |
AlignAtt 帧阈值(较低 = 更快,较高 = 更准确) | 25 |
--beams |
用于波束搜索的波束数量(1 = 贪婪解码) | 1 |
--decoder |
强制解码器类型(beam 或 greedy) |
auto |
--audio-max-len |
最大音频缓冲区长度(秒) | 30.0 |
--audio-min-len |
要处理的最小音频长度(秒) | 0.0 |
--cif-ckpt-path |
用于单词边界检测的 CIF 模型路径 | None |
--never-fire |
永不截断不完整的单词 | False |
--init-prompt |
模型的初始提示 | None |
--static-init-prompt |
不滚动的静态提示 | None |
--max-context-tokens |
最大上下文标记数 | None |
--model-path |
.pt 模型文件的直接路径。如果找不到,请下载 | ./base.pt |
--preloaded-model-count |
可选。在内存中预加载以加快加载速度的模型数量(设置为预期的并发用户数) | 1 |
| WhisperStreaming 后端选项 | 描述 | 默认 |
|---|---|---|
--confidence-validation |
使用置信度分数进行更快的验证 | False |
--buffer_trimming |
缓冲区修剪策略(“句子”或“片段”) | segment |
| 分割选项 | 说明 | 默认 |
|---|---|---|
--diarization |
启用说话人识别 | False |
--diarization-backend |
diart 或 sortformer |
sortformer |
--segmentation-model |
Diart 分割模型的 Hugging Face 模型 ID。可用模型 | pyannote/segmentation-3.0 |
--embedding-model |
Diart 嵌入模型的 Hugging Face 模型 ID。可用模型 | speechbrain/spkrec-ecapa-voxceleb |
要使用 Diart 进行二值化,您需要访问 pyannote.audio 模型:
🚀 部署指南
要在生产环境中部署 WhisperLiveKit:
- 服务器设置:安装生产环境 ASGI 服务器并使用多个工作进程启动
pip install uvicorn gunicorn
gunicorn -k uvicorn.workers.UvicornWorker -w 4 your_app:app-
前端:托管您自定义版本的
html示例,并确保 WebSocket 连接点正确 -
Nginx 配置(推荐用于生产环境):
nginxserver { listen 80; server_name your-domain.com; location / { proxy_pass http://localhost:8000; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection "upgrade"; proxy_set_header Host $host; }} -
HTTPS 支持:为了安全部署,在 WebSocket URL 中使用“wss://”而不是“ws://”
🐋 Docker
使用支持 GPU 或 CPU 的 Docker 轻松部署应用程序。
先决条件
- 系统上已安装 Docker
- 如需支持 GPU,请安装 NVIDIA Docker 运行时
快速入门
使用 GPU 加速(推荐):
docker build -t wlk .
docker run --gpus all -p 8000:8000 --name wlk wlkCPU only:
docker build -f Dockerfile.cpu -t wlk .
docker run -p 8000:8000 --name wlk wlk高级用法
自定义配置:
# 自定义模型和语言的示例
docker run --gpus all -p 8000:8000 --name wlk wlk --model large-v3 --language fr内存要求
- 大型模型:确保您的 Docker 运行时已分配足够的内存
自定义
--build-arg选项:EXTRAS="whisper-timestamped"- 在镜像安装中添加额外内容(无空格)。请记住设置必要的容器选项!HF_PRECACHE_DIR="./.cache/"- 预加载模型缓存,加快首次启动速度HF_TKN_FILE="./token"- 添加您的 Hugging Face Hub 访问令牌以下载门控模型
🔮 使用场景
实时捕捉讨论内容用于会议转录,帮助听障用户通过辅助工具跟进对话,自动转录播客或视频用于内容创作,通过说话人识别功能转录客服电话……