



将文档转换为结构化的JSON或Markdown
text-extract-api
将任何图像、PDF 或 Office 文档转换为 Markdown 文本 或 JSON 结构文档,并实现超高精度转换,包括表格数据、数字或数学公式。
该 API 基于 FastAPI 构建,并使用 Celery 进行异步任务处理。Redis 用于缓存 OCR 结果。

功能:
- 无需云/外部依赖 所需一切:基于 PyTorch 的 OCR(EasyOCR)+ Ollama 通过
docker-compose进行部署和配置,无需将数据发送到开发/服务器环境之外。 - PDF/Office 到 Markdown 的转换精度极高,可使用多种 OCR 策略,包括 llama3.2-vision、easyOCR、minicpm-v 以及远程 URL 策略,包括 marker-pdf
- 使用 Ollama 支持的模型(例如 LLama)进行 PDF/Office 到 JSON 的转换3.1)
- LLM 改进 OCR 结果 LLama 在修复 OCR 文本中的拼写和文本问题方面表现非常出色
- 删除个人身份信息 此工具可用于从文档中删除个人身份信息 - 参见“示例”
- 使用 Celery 进行分布式队列处理
- 使用 Redis 进行缓存 - 可在 LLM 处理之前轻松缓存 OCR 结果
- 存储策略 可切换的存储策略(Google Drive、本地文件系统等)
- 用于发送任务和处理结果的CLI 工具
截图
将 MRI 报告转换为 Markdown + JSON 格式。
python client/cli.py ocr_upload --file examples/example-mri.pdf --prompt_file examples/example-mri-2-json-prompt.txt运行示例之前,请参阅入门

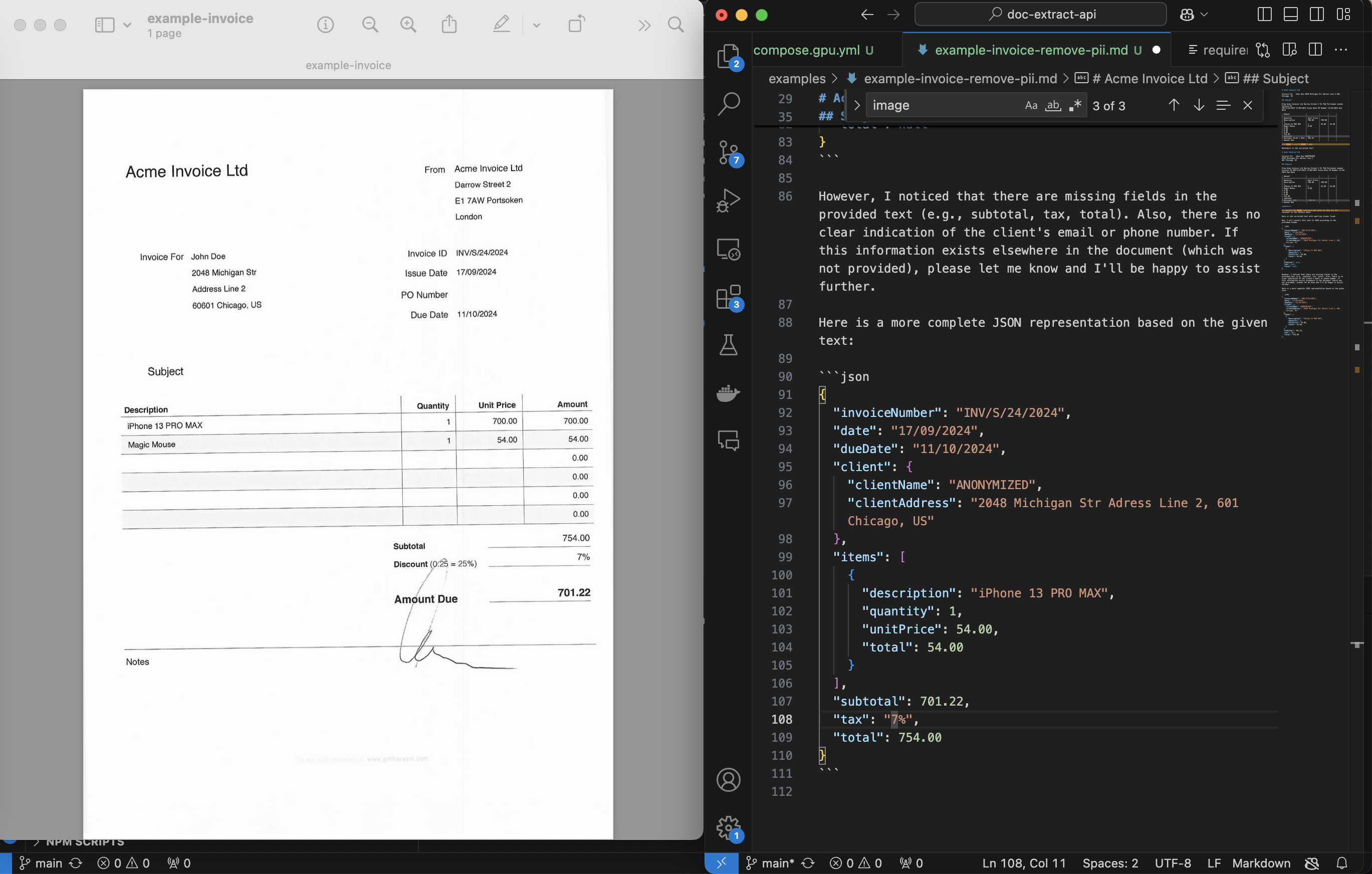
将发票转换为 JSON 并移除 PII
python client/cli.py ocr_upload --file examples/example-invoice.pdf --prompt_file examples/example-invoice-remove-pii.txt运行示例之前,请参阅入门
入门
您可能希望直接在您的机器上运行该应用以进行开发,或者使用 Apple GPU(目前 Docker 不支持)。
先决条件
要启动并运行,请执行以下步骤:
在远程主机上设置 Ollama
要连接到外部 Ollama 实例,请设置环境变量:
OLLAMA_HOST=http://address:port,例如:bashOLLAMA_HOST=http(s)://127.0.0.1:5000如果要禁用本地 Ollama 模型,请使用环境变量
DISABLE_LOCAL_OLLAMA=1,例如:bashDISABLE_LOCAL_OLLAMA=1 make install注意:禁用本地 Ollama 时,请确保所需模型已下载到外部实例。
目前,
DISABLE_LOCAL_OLLAMA变量无法用于在 Docker 中禁用 Ollama。解决方法是,从docker-compose.yml或docker-compose.gpu.yml中删除ollama服务。未来版本将支持在 Docker 环境中使用该变量。
克隆代码库
首先,克隆代码库并将当前目录切换到该代码库:
git clone https://github.com/CatchTheTornado/text-extract-api.git
cd text-extract-api使用 Makefile 设置
默认应用程序创建 虚拟 Python 环境: .venv。您可以在本地设置中通过在运行脚本前添加 DISABLE_VENV=1 来禁用此功能:
DISABLE_VENV=1 make install DISABLE_VENV=1 make run 手动设置
配置环境变量:
cp .env.localhost.example .env.localhost您可能只想使用默认值 - 应该没问题。设置环境变量后,只需执行:
python3 -m venv .venv
source .venv/bin/activate
pip install -e .
chmod +x run.sh
run.sh此命令将安装所有依赖项 - 包括 Redis(通过 Docker 安装,因此无论如何,它并非完全脱离 Docker 运行 text-extract-api :)
(MAC) - 依赖项
brew update && brew install libmagic poppler pkg-config ghostscript ffmpeg automake autoconf(Mac) - 你需要启动 celery worker
source .venv/bin/activate && celery -A text_extract_api.celery_app worker --loglevel=info --pool=solo然后你就可以运行一些 CLI 命令了,例如:
python client/cli.py ocr_upload --file examples/example-mri.pdf --ocr_cache --prompt_file=examples/example-mri-remove-pii.txt扩展并行处理
要同时运行多个任务 - 对于并发处理,请运行以下命令启动单个工作进程:
celery -A text_extract_api.tasks worker --loglevel=info --pool=solo & # 要通过并发处理进行扩展,请运行此行,其次数与您想要运行的并发进程数相同在线演示
要使用我们的托管版本试用该应用程序,您可以跳过“入门”部分,直接在我们的云平台上试用 CLI 工具:
在浏览器中打开:demo.doctractor.com
... 或在终端中运行:
python3 -m venv .venv
source .venv/bin/activate
pip install -e .
export OCR_UPLOAD_URL=https://doctractor:Aekie2ao@api.doctractor.com/ocr/upload
export RESULT_URL=https://doctractor:Aekie2ao@api.doctractor.com/ocr/result/
python client/cli.py ocr_upload --file examples/example-mri.pdf --ocr_cache --prompt_file=examples/example-mri-remove-pii.txt